728x90
DB 04 - SQL 심화 : 효율적인 쿼리 사용
01. 서브 쿼리와 조인
서브 쿼리
다른 SQL 문이 포함된 SAL문
조인
2개의 테이블을 하나로 합치는 것
예시
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
birthdate DATE,
registration_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE posts (
post_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
title VARCHAR(50) NOT NULL,
content VARCHAR(50),
create_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES USERS(USER_ID)
);
INSERT INTO users (username, email, birthdate) VALUES
('kim', 'kim@example.com', '1990-01-01'),
('lee', 'lee@example.com', '1985-05-15'),
('park', 'park@example.com', '1992-08-22');
INSERT INTO posts (user_id, title, content) VALUES
(1, 'Two', 'This is the content of the first post'),
(1, 'One', 'This is the content of the second post'),
(2, 'Three', 'This is a post by lee'),
(3, 'Four', 'This is a post by park');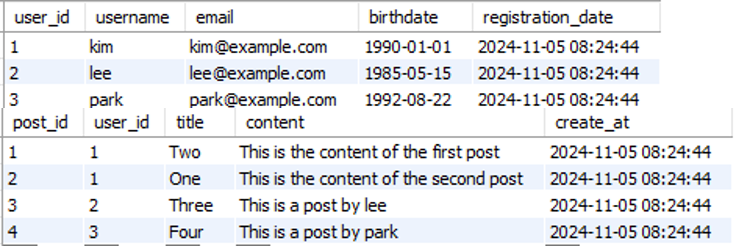
하나의 SELECT문으로 여러 테이블을 조회 하려면??
기본 양식
SELECT table1.field1, table2.field2, ....
FROM table1, table2, ...
WHERE table1.field1 = table2.field2;
예시
SELECT users.username, users.email, posts.title
FROM users, posts
WHERE users.user_id = posts.user_id;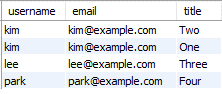
서브 쿼리 이용하기
- 서브 쿼리를 소괄호로 감싸 외부 쿼리와 구분한다.
예시
SELECT users.username
(SELECT COUNT(*)
FROM posts
WHERE post.user_id = users.user_id) AS post_count
FROM users;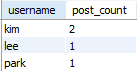
조인 이용하기

예시
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT,
email VARCHAR(100) UNIQUE
);
INSERT INTO customers (name, age, email) VALUES
('kim', 30, 'kim@example.com'),
('lee', 25, 'lee@example.com'),
('park', 40, 'park@example.com'),
('kang', 20, 'kang@example.com'),
('kwon', 18, 'kwon@example.com'),
('gwakj', 21, 'gwakj@example.com'),
('na', 45, 'na@example.com'),
('jo', 22, 'jo@example.com'),
('yang', 50, 'yang@example.com');
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
customer_id INT,
product_id INT,
quantity INT,
amount INT
);
INSERT INTO orders (customer_id, product_id, quantity, amount) VALUES
(1, 1, 10, 1000),
(2, 2, 20, 2000),
(2, 3, 30, 3000),
(3, 4, 40, 4000),
(3, 5, 50, 5000),
(4, 6, 60, 6000),
(4, 7, 70, 7000),
(5, 8, 80, 8000),
(5, 9, 90, 9000),
(10, 9, 90, 0000);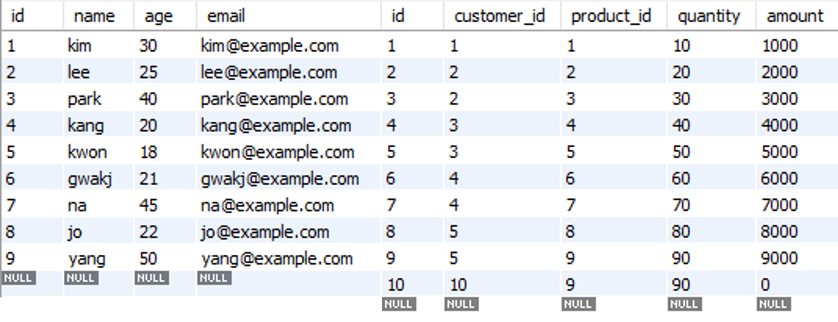
1) INNER JOIN
두 테이블의 레코드들 중에서 조인에 대한 조건을 모두 만족하는 레코드를 결과로 반환한다.
SELECT custonmers.name, customers.agem customers.email, orders.id, orders.product_id, orders.quantity, orders.amount
FROM customers
INNER JOIN orders ON customers.id = orders.customer_id;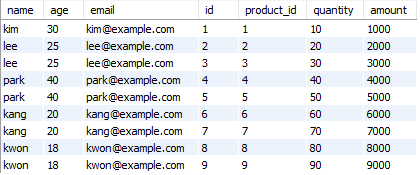
2) OUTER JOIN
- LEFT JOIN : 왼쪽 테이블을 기준으로 오른쪽 테이블의 레코드를 합치고, 없다면 NULL값을 준다.
SELECT customers.name, orders.id AS order_id, orders.product_id, orders.quantity, orders.amount
FROM customers
LEFT OUTER JOIN orders ON customers.id = orders.customer_id;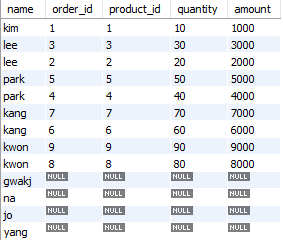
- RIGHT JOIN : 오른쪽 테이블을 기준으로 왼쪽 테이블의 레코드를 합치고, 없다면 NULL값을 준다.
SELECT customers.name, orders.id AS order_id, orders.product_id, orders.quantity, orders.amount
FROM customers
RIGHT OUTER JOIN orders ON customers.id = orders.customer_id;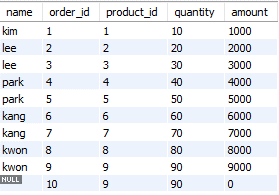
- FULL JOIN : 두 테이블의 모든 레코드를 선택한다. 대응되지 않으면 NULL값을 준다.
SELECT customers.name, orders.id AS order_id, orders.product_id, orders.quantity, orders.amount
FROM customers
LEFT OUTER JOIN orders ON customers.id = orders.customer_id;
UNION
SELECT customers.name, orders.id AS order_id, orders.product_id, orders.quantity, orders.amount
FROM customers
RIGHT OUTER JOIN orders ON customers.id = orders.customer_id;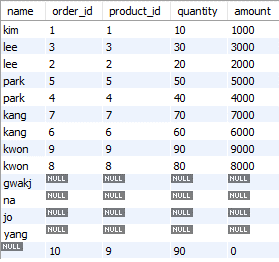
02. 뷰
- SELECT 문을 FROM 문에 포함된 서브 쿼리로 간주하며 SQL문을 작성하는 경우의 번거로움을 줄이기 위해서 사용한다.
- SELECT 문의 결과로 만들어진 가상의 테이블.
CREATE VIEW {뷰_이름} AS SELECT;
예시
CREATE VIEW myview AS
SELECT customers.name, customers.email, orders.quantity
FROM customers, orders
WHERE customers.id == orders.customer_id;SHOW TABLES;를 실행하면 테이블이 생성된 것을 볼 수 있다.

이렇게 만들어두면 sql문을 반복적으로 작성할 필요가 줄어든다.
03. 인덱스
- 검색 속도 향상을 목적으로 만드는 하나 이상의 테이블 필드에 대한 자료구조
종류
- 클러스터형 인덱스 : 테이블당 하나씩 만들 수 있는 인덱스 ex) PRIMARY KEY
- 세컨더리 인덱스, 논클러스터형 인덱스 : 테이블당 여러 개가 존재할 수 있지만, 클러스터형 인덱스를 활용한 검색보다 일반적으로 느림.
테이블에서 필드의 인덱스를 생성
CREATE INDEX {인덱스_이름} ON {테이블_이름} (필드);;인덱스 조회
SHOW INDEX FROM {테이블_이름};인덱스 삭제
DROP INDEX {인덱스_이름} FROM {테이블_이름};반응형
'내가 만드는 개발자 교안 > Computer Science' 카테고리의 다른 글
| Every CS - 데이터베이스 06 - NoSQL (1) | 2024.12.18 |
|---|---|
| Every CS - 데이터베이스 05 - 데이터베이스 설계 (1) | 2024.12.17 |
| Every CS - 데이터베이스 03 - SQL (3) | 2024.10.31 |
| Every CS - 데이터베이스 02 - RDBMS (1) | 2024.10.30 |
